·�ɣ�Ѹ�ٻָ�
������֪��Ҫ��úܸߵ����������ԣ���Ҫʹ�þ����ȹ��ϻָ����ܺ����Ӳ�ͬ����·������·�����ͱ���·���������ǽ������������� �� ·��������������������Щλ�ڲ���ȫ�� WAN ��Ե��·��������Ӧ�������ڲ�����Ӳ����������罻��������·������Դ·�ɴ������� RP �����߿�����·����������֧�ֿ��������ָ�������
���ÿ��Ը�����ƺ�ת����壬��ʹ��ƽ�ȵ��������ơ���Ҳ����Ϊ˼�Ʋ����ת���� NSF ��������·���������Դ���ȵ��ӳ������Ӧ�õ���������ʱ�䡣���������ָ����������� RP ���̷����ж�ʱ�����ַ�����������䣬�Ӷ������ж϶������Ӱ�졣
˫RP����������ת��
RP ������·�����ġ����ԡ���������洢���·��·����Ϣ�����ݿ⣬������Ե�·�������ڽӹ�ϵ���Լ������ض��Ĺ���ְ�ܡ�����Ӳ�����������������ڷ�������ʱ�Ŀ����ԡ�˼�Ƶ�˫ RP �豸���� 12000 �� 10000 �� 7600 ϵ�и߶�·�������Լ� Cisco 7500 �� 7300 ϵ��·������
���� RP ��״̬��Ϣ��ͬ���̶���һ���̶��Ͻ�ȡ����·�����ܹ��Զ����ٶȴӽ����������ߴӹ����лָ�������Ҫ���������˵ı�����ʽ֮�����ƽ�⡣һ�ּ�����ʽ�� RP �ġ��䡱���ݣ����������κι��ڵڶ������ӡ��ڽӹ�ϵ�����·��·�ɱ���״̬��Ϣ������������£�������Щ��Ϣ����Ҫ���¹�����������ܻᵼ�¼����Ļָ�ʱ�䡣����һ�ּ�����ʽ�������� RP ֮�䲻��ϵ�ͬ�����е���Ϣ������ܻ�ռ�ù���Ĵ�����Դ��Ӱ�쵽����Ŀ���չ�Ժ����ܡ�
ͨ�����õķ�ʽ���������ּ��˵� RP ͬ����ʽ֮�䱣���ʵ���ƽ�⣬�����֣�������ȫ�����ָ���Ϣ���ص����� RP �С�����ͬ���������л� RP �ͼ���·�ɱ��Ĺ����У��������е��������ת����
��װ������·����ƽ̨�ϵ� Cisco IOS®���� 12.0(22)S �汾���߸��߰汾����֧��˼�� NSF ���������� RP ����Ԥ��ά������ RP �����������ʱ����·������ͣ��ʱ�䡣�ڴ��������£�Ҫʵ��˼�� NSF ������·���������ĶԵ� ·�������뱣��������п���ͨ������·��������������ת����Ϣ��������·�����ϣ��ڴ��� RP ���� RP �л��Ĺ����У���������ת�������뻥����룬�Ա���ת������ܼ���ת������������
·��Э����չ
Ϊ��ʵ�� NSF ������˼��·�������Բ��ó���·��Э�����������߽�����Э���� BGP ���� IS-IS �Ϳ������·�����ȣ� OSPF ��������ƽ��������չ����Щ��չ�������ж��� RP �ܷ�Ѹ�ٻָ���ͬʱ����ʱ����ת������ͱ����������ӵ��ȶ��ԡ�
Ҫ�ô�˼�� NSF/ ƽ������������Է������ã�����·�����ĶԵ�·����Ҳ����֧����Щ��չ������Ҫ��������������ԭ�����ȣ� RP �л������������˱仯��������ʾ RP �ָ����Ե�·������������ƽ��������չ����������������Ӷ��������㲥ͣ�ú���������·��������Ϣ������Է�ֹ����Ҫ�Ĺ㲥��Ϣ��·�ɱ仯����Σ����öԵ������ڻָ��ڼ����������·����ת�����飬�Ӷ��ṩ NSF ����������֪��Ӧ��������Щ��Ϣ����Ϣ����������Ѹ�ٻָ���
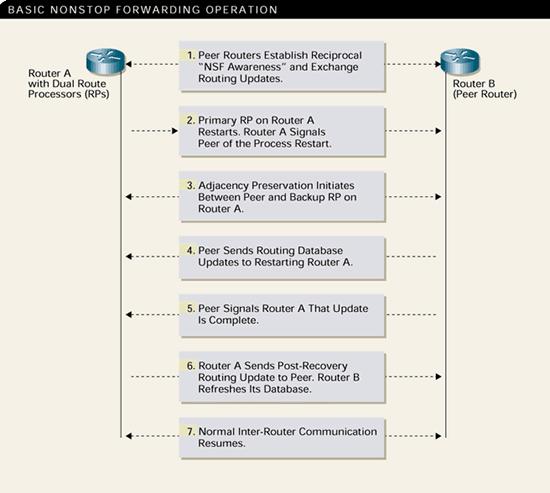
ͼ 1: ֧��˼�� NSF �ĶԵ����������˴˴�ͻ��������Ѹ�ٻָ����Ӷ�����ȵ�����ͣ��ʱ�䡢����ת������ͱ�������������ȶ��ԡ�
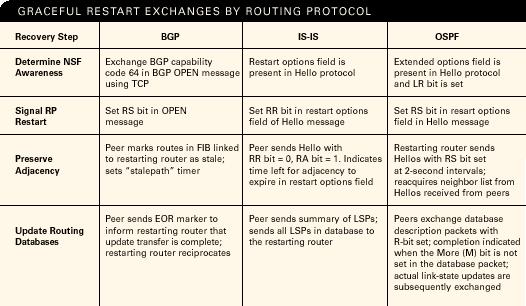
ͼ 2: ���۲����κ�Э�����û����ݷ��鶼���������ָ������в��ϵ��ڶԵ���֮�䴫�䡣
ƽ�������Ļ�������
����Э����ƽ���������趼�����Ƶģ���ͼ 1 ��ʾ���������г��˻����IJ��裺
• ȷ���Ե�·������֧�� NSF ����
• ���� / ��������λ���Ա�Ե�·����֪�����ڽ��лָ���
• ��ʱ�����ڽ���Ϣ���Ա������Լ���ʹ�����֪����·�ɼ���ת����
• �ڻָ����֮���µ�·�����ݿ���Ϣ
���ǣ���Ϊÿ��·��Э����ʹ�ò�ͬ�Ļ���������·�������ڽӹ�ϵ���߶Եȹ�ϵ���Լ�����·����Ϣ������ÿ��Э��ƽ�������������Ϣ��������ͬ����ͼ 2 ��ʾ����
���磬 BGP ���õײ� TCP Э���������Եȹ�ϵ���� OSPF �� IS-IS ʹ�� Hello ��Ϣ�������ڽӹ�ϵ��������·��Э�������һ�������ǣ��ڷ�������·�������ָ��;�������������ȫ�����ںϽ��д�ͳ�ָ�֮ǰ������ת�������ʱ�䡣
BGP ƽ������
��Ϊ BGP ������Ӱ����ܻ�dz���Զ������ BGP �ǽ��и߿����ԸĽ�����Ҫ���� BGP ���Գ��ش�����·�ɣ�������ij�� BGP �����������Ϻ���������ںϵ�ʱ��ͨ����������֧�ֽ���·�ɵ�·��Э�������⣬��Ϊ BGP ��һ�����·��Э��������һ���������ϵ� BGP ���̿��ܻᴫ����������磬�����Ǿ�����ijһ����
�� BGP �����������ʱ��Э���Ľ����ڳ�ʼ BGP ���ӽ���֮��ʼ������·��������Ե�·������ͨ���ڽ������̵ij�ʼ BGP OPEN ��Ϣ�н��� BGP ���ܴ��� 64 ��������˼�� NSF ��֧�֡�
��ͨ������£���·������������ BGP ����ʱ����Ե�·������ TCP ���ӽ���������Ӷ����¶Ե�·�����������������·�����йص�·�ɡ����ǣ��ڽ��� BGP ƽ������ʱ��������������IJ������෴���Ե�·�����Ὣ��Щ·�ɱ�Ϊ�����ڡ��������ݶ�����·��������Ѹ�����½��� BGP ���̵�Ԥ�ڣ���������Щ·��ת�����顣ͬ��������·���������� BGP Э�����������ں�ʱ����ת�����顣
������·���������µ� BGP ����ʱ���������ٴ������ĶԵ�·�������� BGP ���ܴ��� 64 ����������һ�Σ�ƽ���������ܽ����еı��λ���ý��öԵ�·����֪�� BGP �����Ѿ�������
�ڼ���ת�������ͬʱ���Ե�·������������·��������һ����ʼ·���������Ե�·������ͨ��һ�� end-of-RIB �� EOR ����DZ������Ѿ�������������ϡ�������ʵ������һ���յ� BGP UPDATE ��Ϣ��������·���������жԵ�·�����յ� EOR �Ժ�����֪�������������µ�·����Ϣ�ٴο�ʼѡ�����·����
ͬ��������·����Ҳ�������ĶԵ�·������������������������ EOR ��DZ�ʾ������ɡ��⽫�öԵ�·���������ô�����·�������յ�������ȡ�����ڵ�·�ɡ�
IS-IS ������
��������������С�� �� IETF �������Ի������ݰ�����ʽ��Ϊ IS-IS ����״̬������·��Э�����һ�����Ƶ�ƽ���������̡� IS-IS ��չ������ߡ�����˼�Ƶ� Mike Shand ָ���� �ڱ��� Packet® ����ʱ�� IETF ���ṫ������ݰ������һ���汾����ǰ������ IS-IS ���� Hello Э���������ڵ�·�������Լ������ͱ����ڽӹ�ϵ����·��������ʱ������ͨ�� Hello Э�����ݵ�Ԫ�е�һ���������� RR ��λ����Ե�·���������źš���һ�� IS-IS �����У��Ե�·��������ֱ��������·�����������ݿ���Ϣ��������ȴ�ȷ����Ϣ��
��·��������֮�����ᷢ��һ����������� RR λ���õ� Hello ���飬�Ӷ��öԵ�·����֪�����Ѿ��������Ե�·������ͨ�������Լ��� Hello ��Ϣ������һ�����������ȷ�ϣ� RA ��λ��ȷ����������źš��ڶԵ�·����֪������һ��·�����Ѿ����������û���κ�·����Ϣ��֮�����ᷢ��һ����������״̬���飨 LSP ���Ļ����б�������ٷ����б���ָ���� LSP �����⣬һ�������б����ϣ�����·�����ͻ������������ݿ⡣������Ƕ�����˵�����ֹ����� BGP ƽ�����������е� EOR �൱���ơ�
˼��Ϊ�������������н��棨 CLI �������������õ� IS-IS �ṩ����һ�ַ������������е��ڽӺ� LSP ��Ϣ��������ݴ浽���� RP �С����л����֮���µ��� RP �������ݴ�����ݱ��������ڽӹ�ϵ��������Ѹ�ٵ��ؽ�����·�ɱ���
RP ���л�����ֻ��Ҫ������ʱ�䡣 IS-IS �����ڽ������ļ��������ؽ�����·�ɱ���������������ͬ���������ʱ�� IS-IS ��ȴ�һ��ָ���ļ��������Եڶ���˼�� NSF �������ڴ��ڼ䣬�µı��� RP �������������������������� RP ����ͬ����
��ͬ�����֮�� IS-IS �ڽӹ�ϵ�� LSP ���ݻ��ݴ浽���� RP �����ǣ�ֻ���ڼ��ʱ�����֮�� IS-IS �Ż᳢���µ�˼�� NSF ���������⣬����·���������õ�һ�������б���֤��������� LSP ����Ч�ԣ��Ӷ����� IS-ISЭ���״̬��
OSPF �Ĺ�����ʽ
��ij��֧�� OSPF NSF ��·�������� RP �л�ʱ������ִ�����������Ա������� OSPF �ھ�����ͬ����������״̬���ݿ⣨ LSDB �������ȣ��������ڲ����������ڽӹ�ϵ������£�����ѧϰ�����ϵĿ��� OSPF �ھӡ���Σ����������»������� LSDB �����ݡ�
�� RP �л�֮������·�������Ժ̵ܶļ��ʱ�䣬��֧��˼�� NSF �������豸����һ�� Hello ���飬�������е���չѡ�����ͳ���ֵ�� TLV �������������ź�λ���Ե�·��������ʶ����������·�������ڽӹ�ϵ����Ҫ�������á�������·�����յ�һ�� Hello ��Ӧ����Ϊ������ Hello ��Ϣ�Ļظ���֮�����ͻῪʼ�����ĶԷ�·�����������ݿ�ͬ����
�����ݿ�ͬ������֮������·����������������·����Ϣ�⣨ RIB ����ת����Ϣ�⣨ FIB ������������������״̬��Ϣ������·���������ݿ�ͬ���ڼ��յ�����Ϣ��ͬ������·�����������Щ��Ϣ���͵��Ե�·������
�߿�������������ںܶ����мӹ̣������������������������ơ����⣬����Ҫ������������������������ܵ�·��������Щ�������ܿ��Խ��й��ϻָ��ͼ�����ʱ�ж϶������Ӱ�졣
�ܶ�˼��·��������·��Э����չ����ʽ֧���ڲ���ƺ��������ܣ��������������Ӧ�̺���ҵ�ӹ����ǵ����硣
����·��������������ʱ��
ϵͳ�Ŀ�������ͨ��·������ƽ�����ϼ��ʱ�䣨 MTBF ���������豸������������ʱ�䡪����ƽ�����ϻָ�ʱ�䣨 MTTR �������ġ� MTTR ��ʾϵͳ���ܴ�����ת�������ʱ�䡣�� MTBF ���� MTBF �� MTTR ֮�ͣ��ٳ��� 100 ���͵ó�ij���ض�ϵͳ�Ŀ����ٷֱȡ�
……
�������缼��Ӧ��ʹ�ã����û�����>>>���缼��Ӧ��
�������缼��Ӧ��ʹ�ã�IOS�û�����>>>IOS ���缼��Ӧ��
ɨ���ά�룬ֱ�ӳ���ɨ��Ŷ��


















