bilibili_video_download.exe-��������BiliBili��Ƶ������������-bilibili_video_download.exe���� vpython����ɫ(.*?)
bilibili_video_download.exe��һ��Python��д���ɵĿ�����������BiliBili��Ƶ������������������Ŀ����������ȡ�ͽ�����ҳ�Ŀ⣬�����������̳߳صĿ�ͽ������������Ŀ⣬���������Python�Դ��ġ�
����˵��
����ǰ��
����������£���ʹ����������������Web�˵�bilibili�ƺ��������װ��Σ�������Ƶ����ѧϰ���������Python��������bվ��Ƶ����������Ա��Ƶ�������飨�ַ����ҿ����ġ�
�ο���Ƶ��https://www.bilibili.com/video/BV1Fy4y1D7XS
�ڷ���bվ��ҳԴ����Ĺ����з�������Ƶ����Ƶ�Ƿֿ��ģ����غ�һ��ֻ��������һ��ֻ�л��棬����Ȼ�����������ǵ�Ҫ��������ǣ����� ffmpeg ���ǿ��Ŀ�Դ���߰����غ������Ƶ���кϲ�������Ҫ�������飬�ȵ����ذ�װ�����ú� ffmpeg �������������أ���ѹ����ļ����ڵ�bin ���ӵ�����������
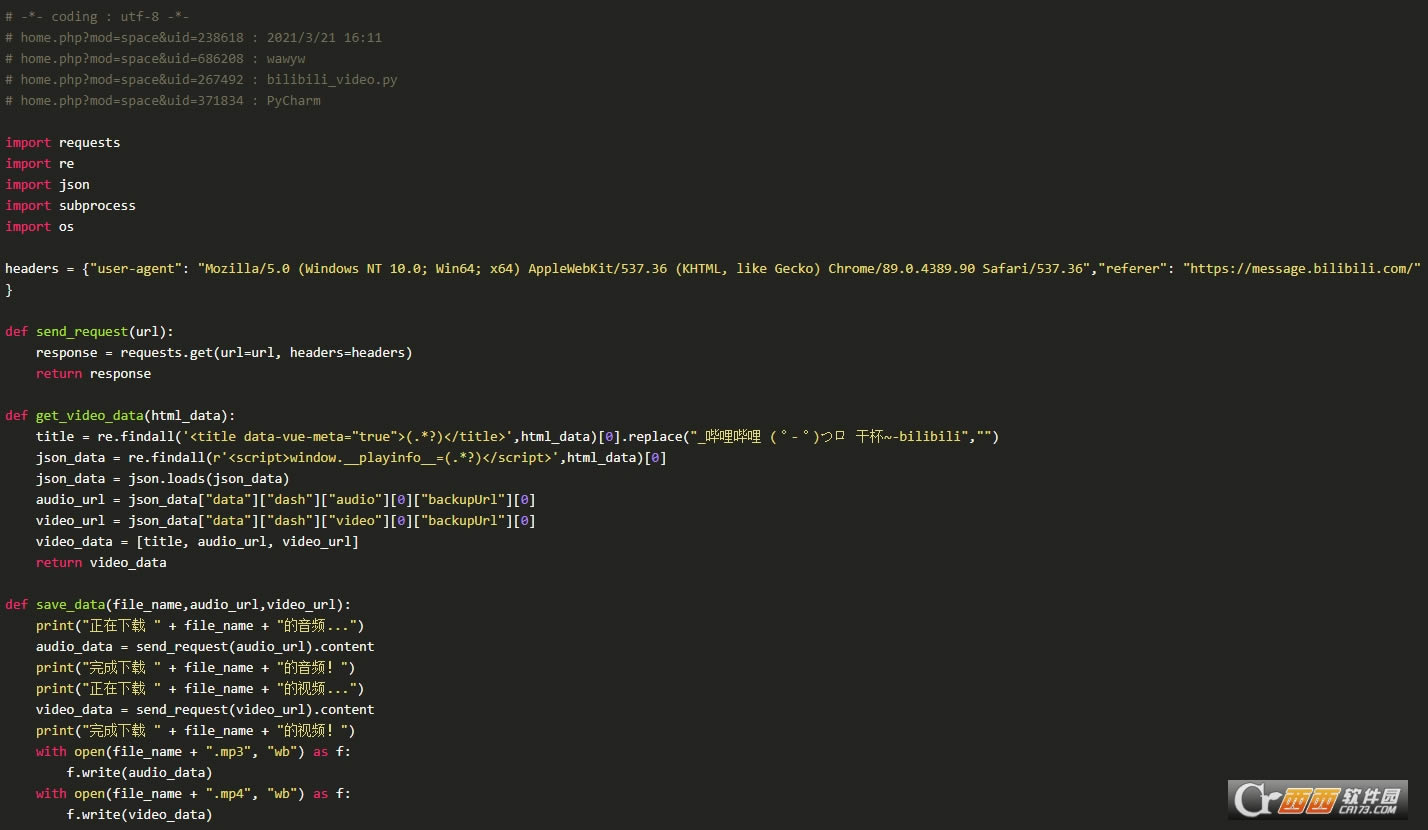
Python��ʹ�õ���ģ���У�requests��re��json��subprocess��os
������
��Ƶ��url�Ƚ����ۣ�����ȡ��headersҲ���ң�������Ҫһ��Ҫ��Ϣ��
ͨ���������F12���鿴����Ŀ����ҳ���ҵ����ǵ���һĿ�꣬���ӣ�����Ƶ�������ӡ�
һ�����Һ�����head��ĵ��ĸ�script ��ǩ���ƺ���������Ҫ�Ķ�����
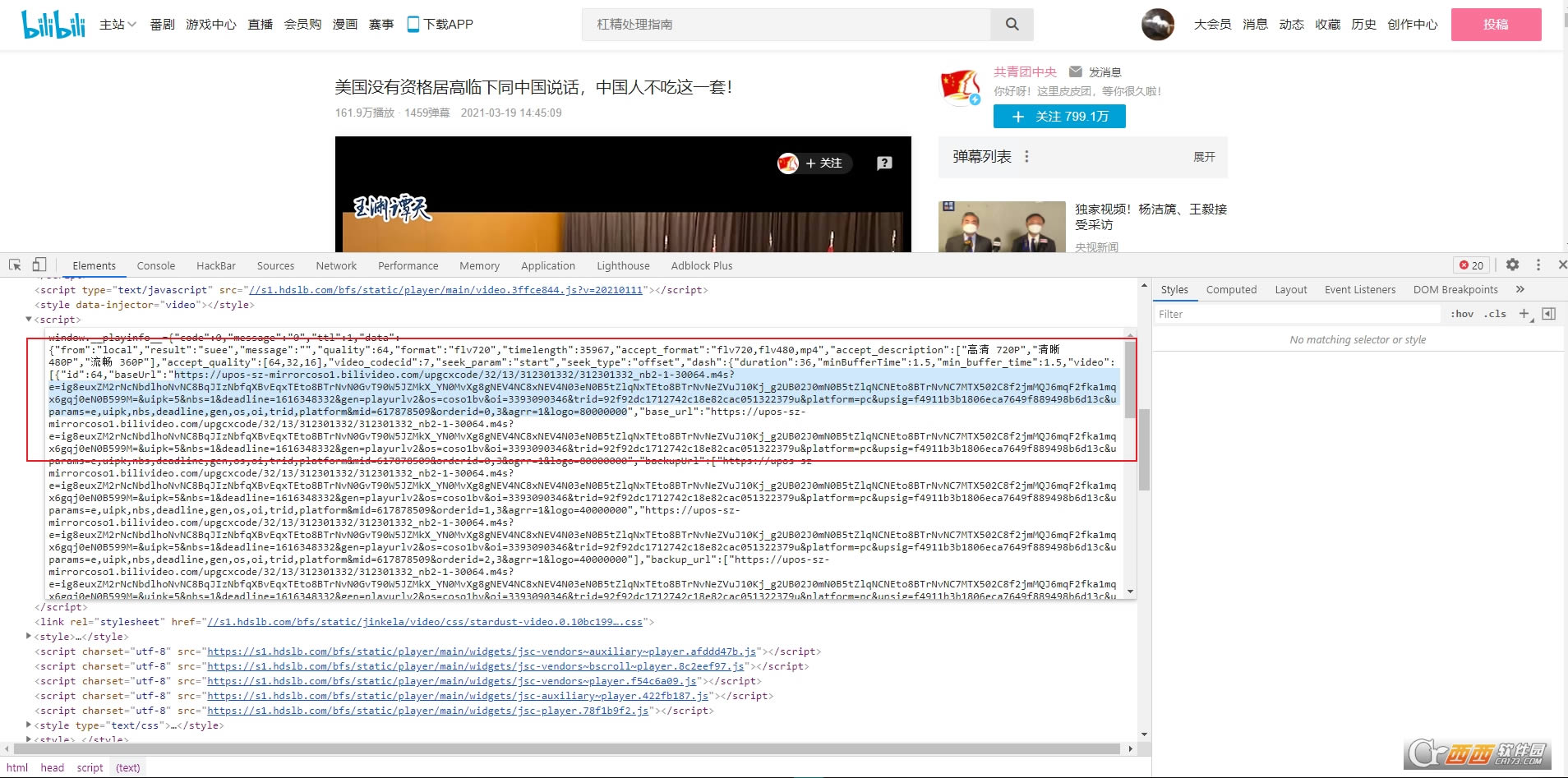
�ɷ��ʴ����ӣ�ȴ����403����û��Ȩ���ʴ�վ��

������ô���£��鿴Request Headers ��Ϣ������û��referer��һ����dz��������ݰ��м���referer��Ϣ���ܷ���ʡ�������ֱ����bp�ˣ�
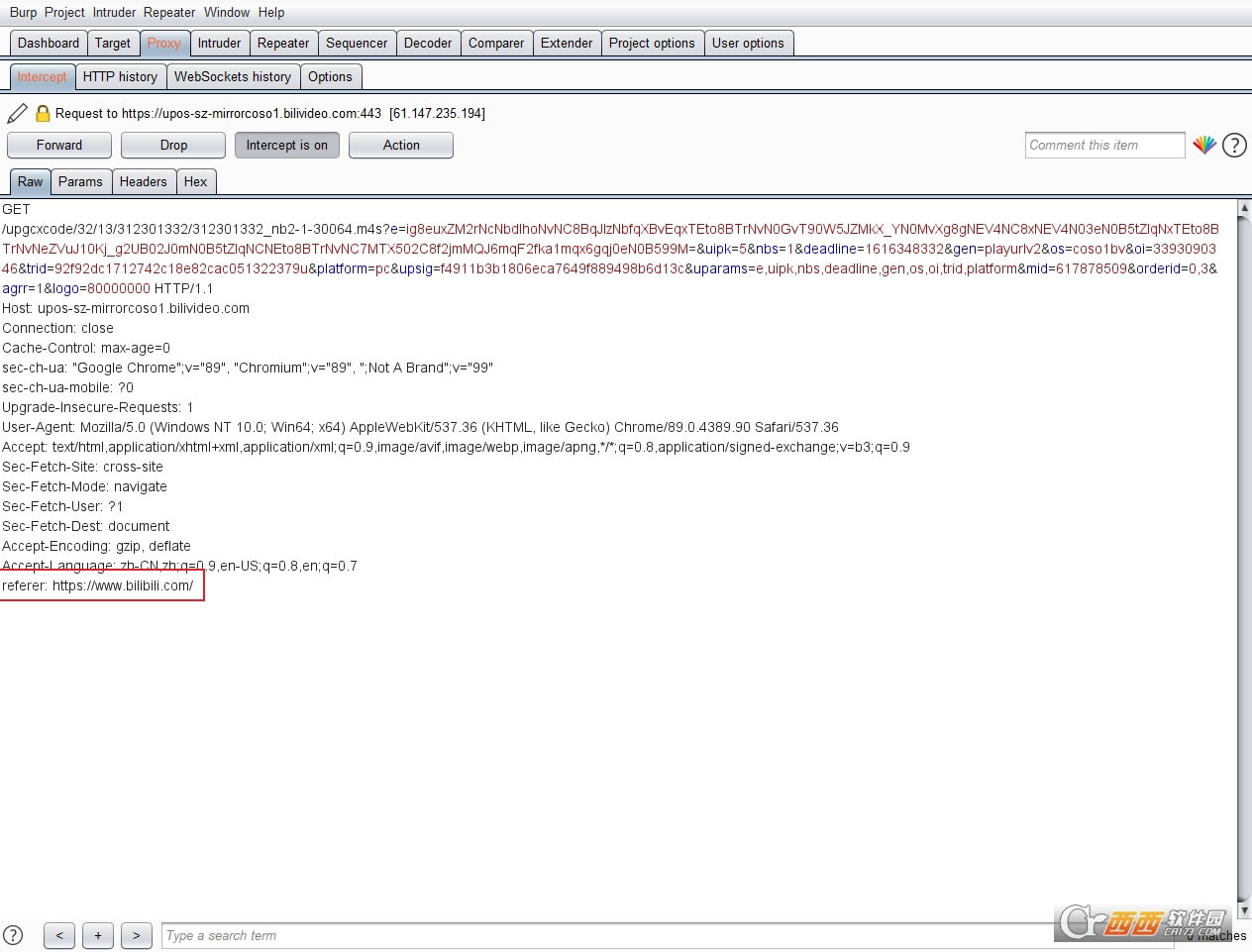
Forward�����ļ�����ҳ�档
���غ���ļ���ȷΪĿ����Ƶ��
��ȡ����
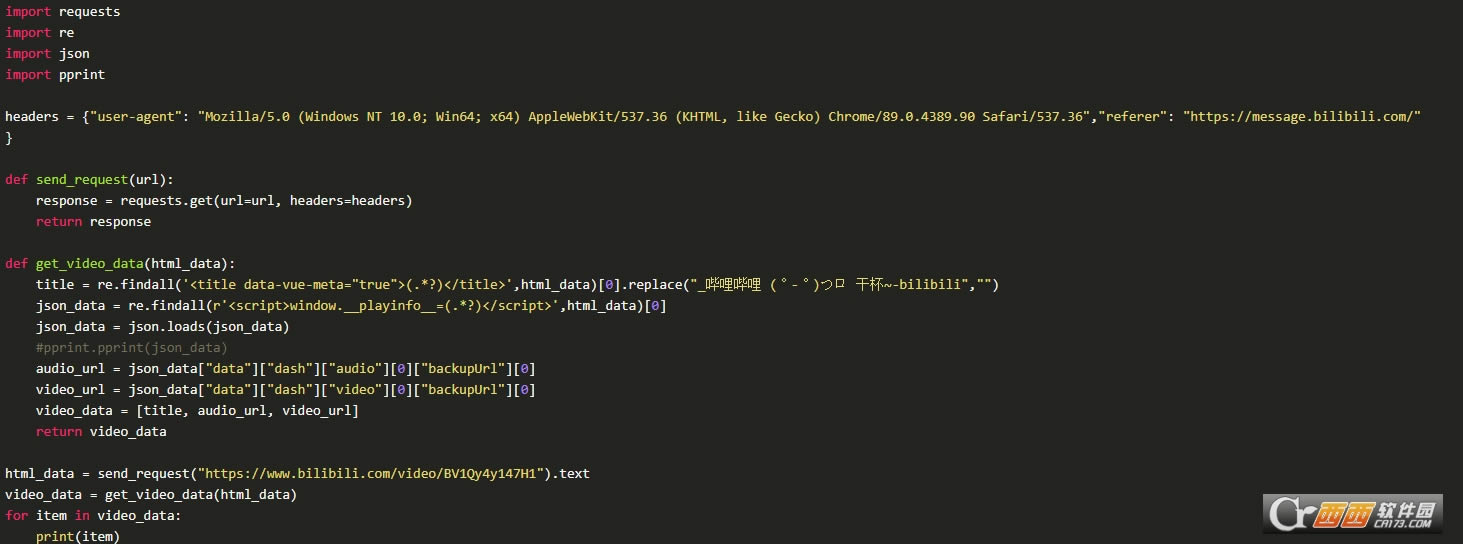
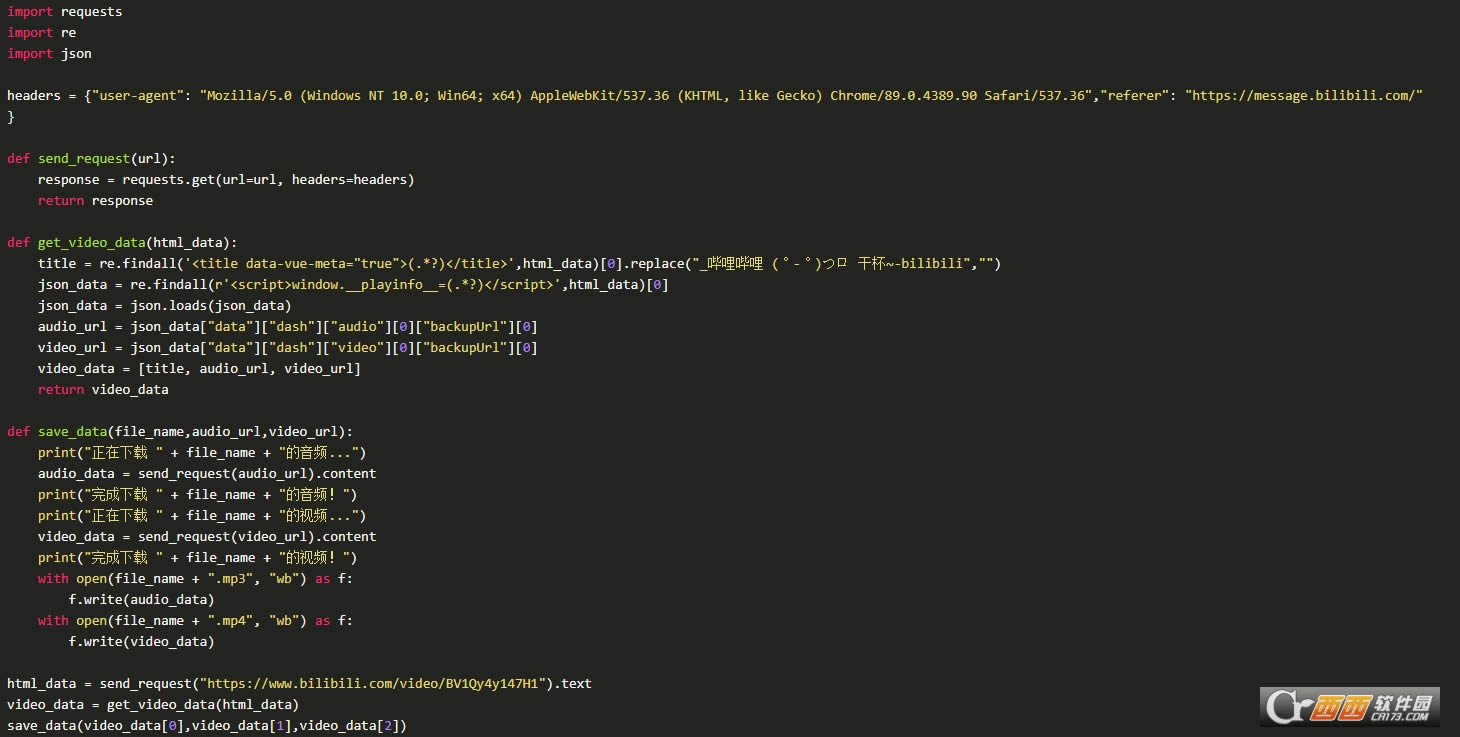
ͨ��requests����Ŀ��վ�㷢���������������header��referer����Ϣ����αװ����������������������������������Ӧ����õ�һ��Response��������Ҫ��ȡ��ҳ�����ݡ�
���Դ��룺

������
��������
�õ������ݿ�����HTML��json�ȸ�ʽ��������ҳ������⡢�������ʽ�Ƚ��н�����
title��Ϣ�ȽϺ��ң�����head�С�
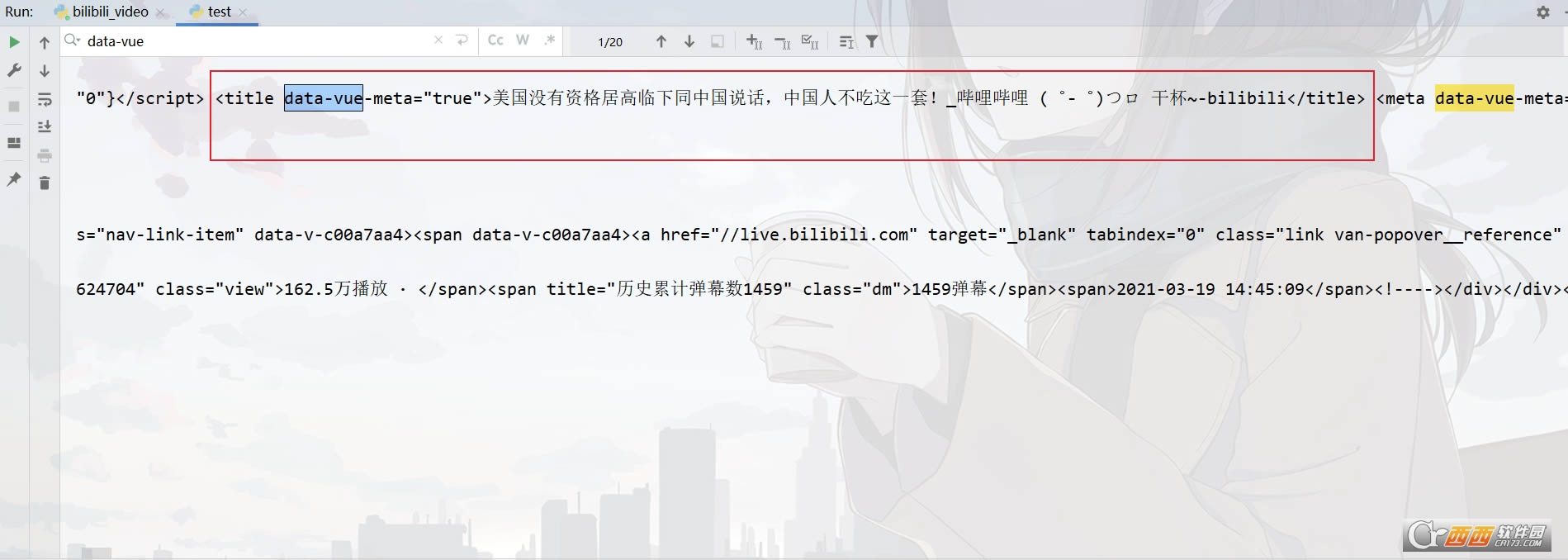
�����������ʽ���������ȡ��
���ƴ��� ���ش���title = re.findall('
����Ƶ����������json�����С�
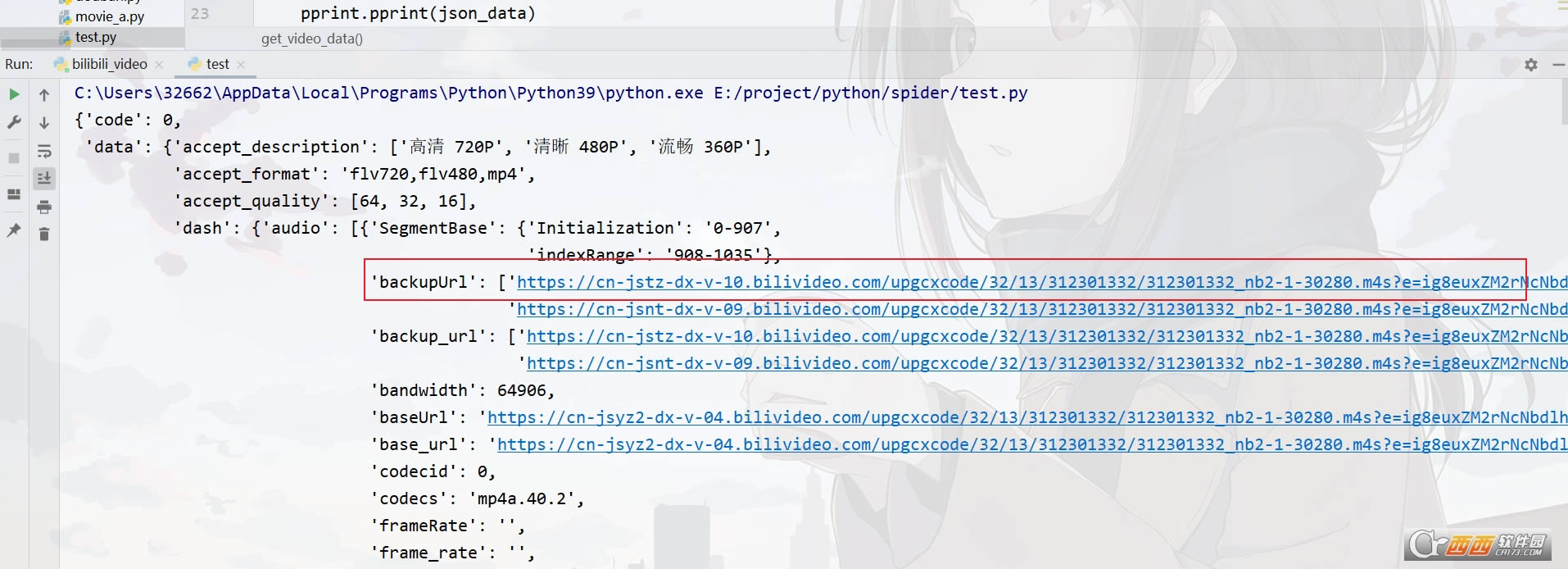
�����������ʽ���ֵ䣨�б�����“��”������ȡ��

���Դ��룺
������

��������
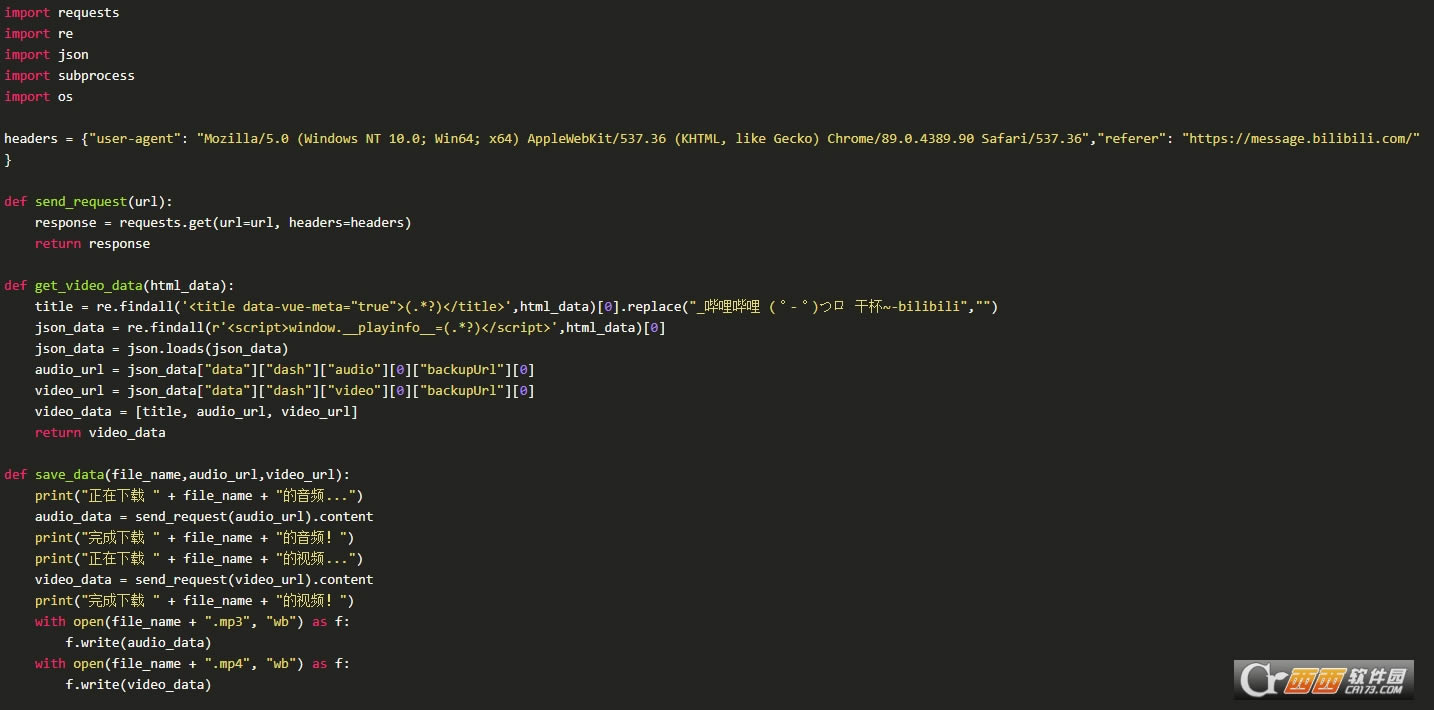
ͨ���������ӣ�������Ƶ���ص����ز����档
���Դ��룺
������


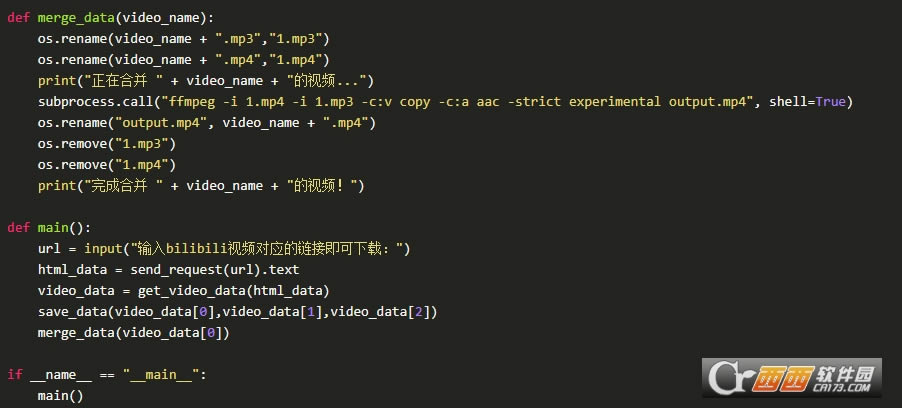
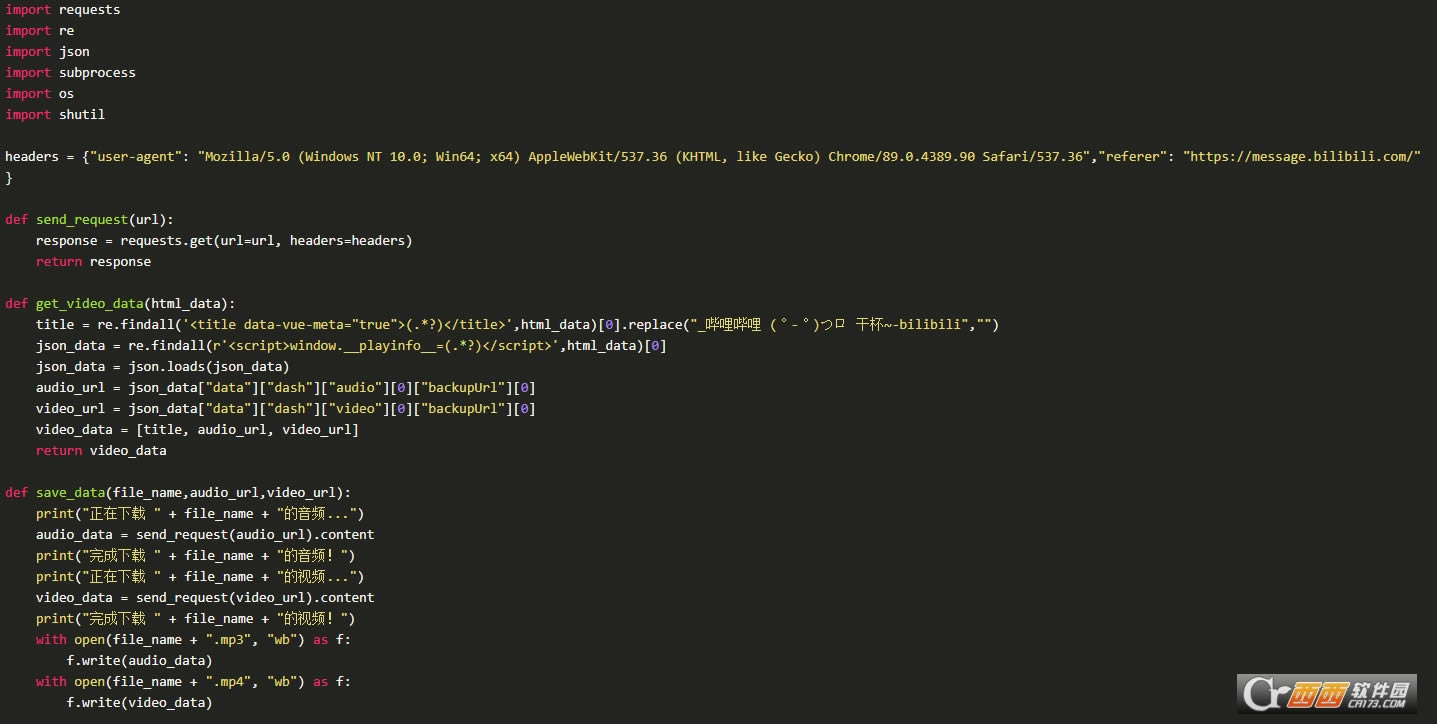
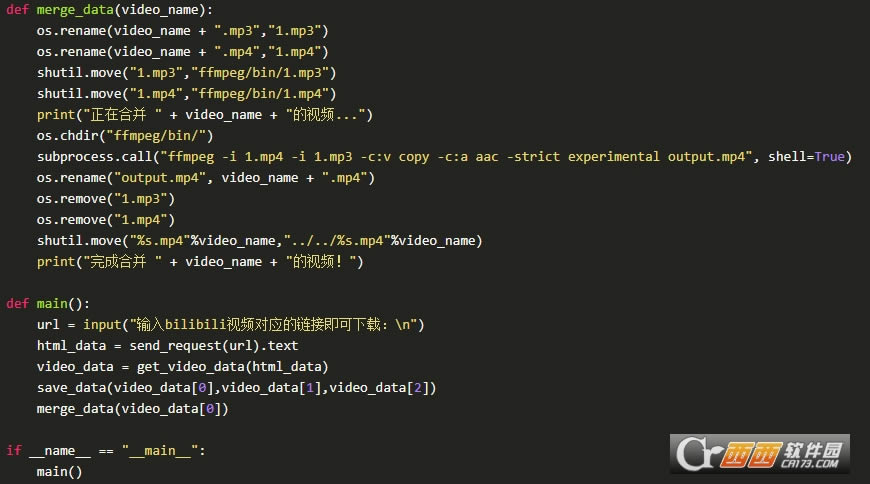
�ϲ�����Ƶ
�ѷֿ�����Ƶ����Ƶ���кϲ��������β��������������������Ƶ������Ϊ�ļ���ȥִ��ffmpeg����ᵼ������ִ�����ʱû�ҵ�����������������Ž��ļ�����������Ϊ1.mp3��1.mp4���ּ����֣�������ɺϲ�����ɾ��֮)
���Դ��룺
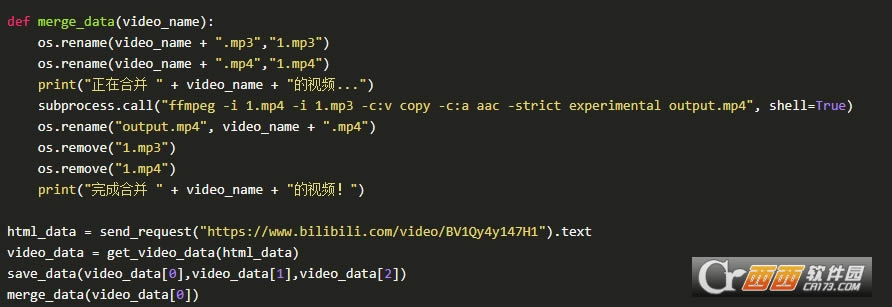
������
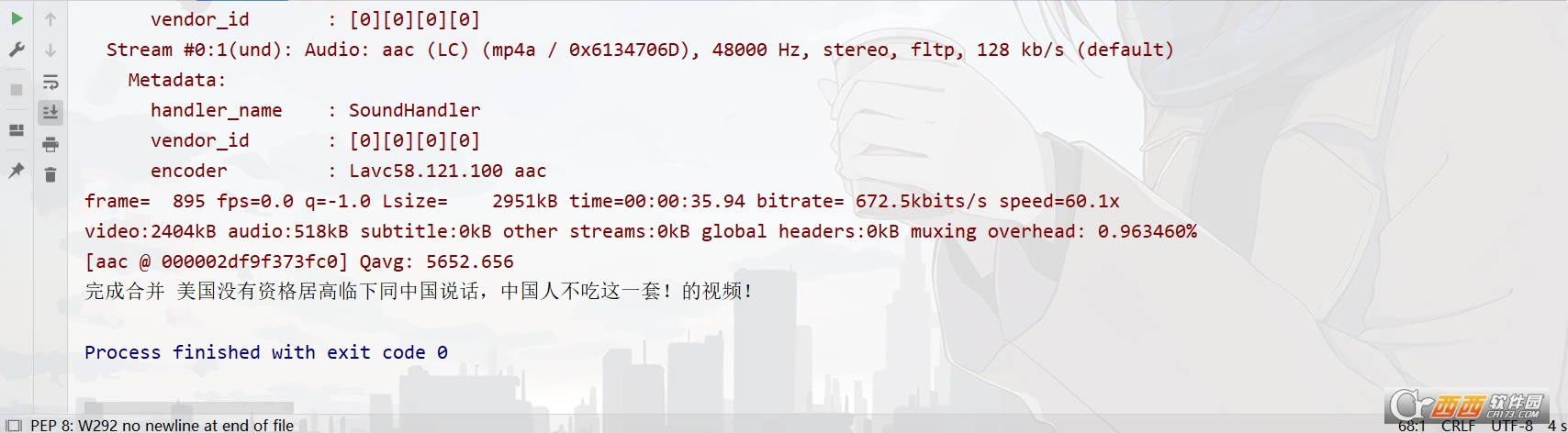
�ϲ�����Ƶ�������ţ�������ɫ��
���մ���
����
�����exe
��������Ҫ�Ȱ�װPyinstaller��ֱ����cmdʹ��pip����

Ȼ��ffmpeg��py�ļ����õ�ͬһ�ļ����¡�
��Ϊffmpeg��Ҫһ�����ģ���Ҫ�Դ����е���ӦĿ¼��С���ġ��ĺ�Ĵ������£�
�ĺú�cmd�л������Ǹոշ��ļ���Ŀ¼��ִ���������

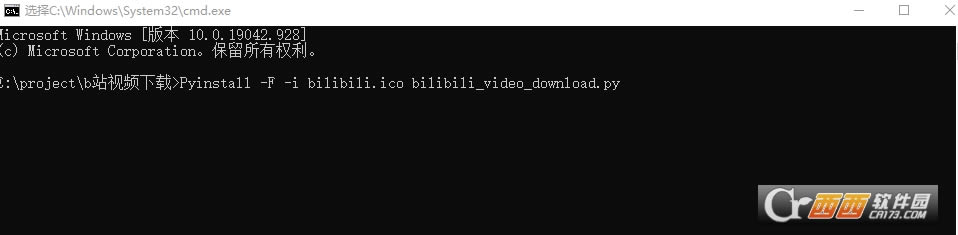
������-i bilibili.ico�ǶԳ����ͼ��������ã�Ϊ��ѡ�
ִ����ϻᷢ�ֵ�ǰĿ¼���˼����ļ��У���������Ϊdist���ļ��У�����������һ����Ϊbilibili_video_download��exeӦ�ó�����ͼ��Ҳ���������õ�ͼ����������Ҫ��exe�ļ��ƶ�����һ��Ŀ¼����ffmpeg��ͬ��Ŀ¼��
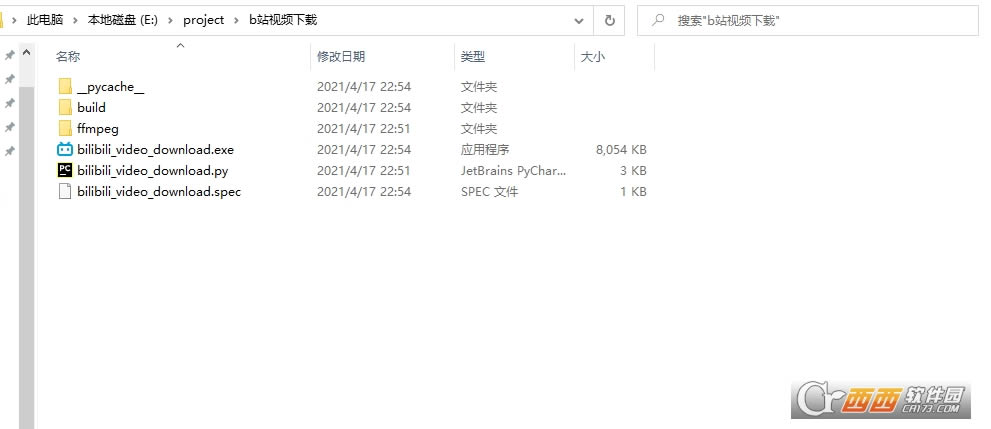
ʹ��˵��
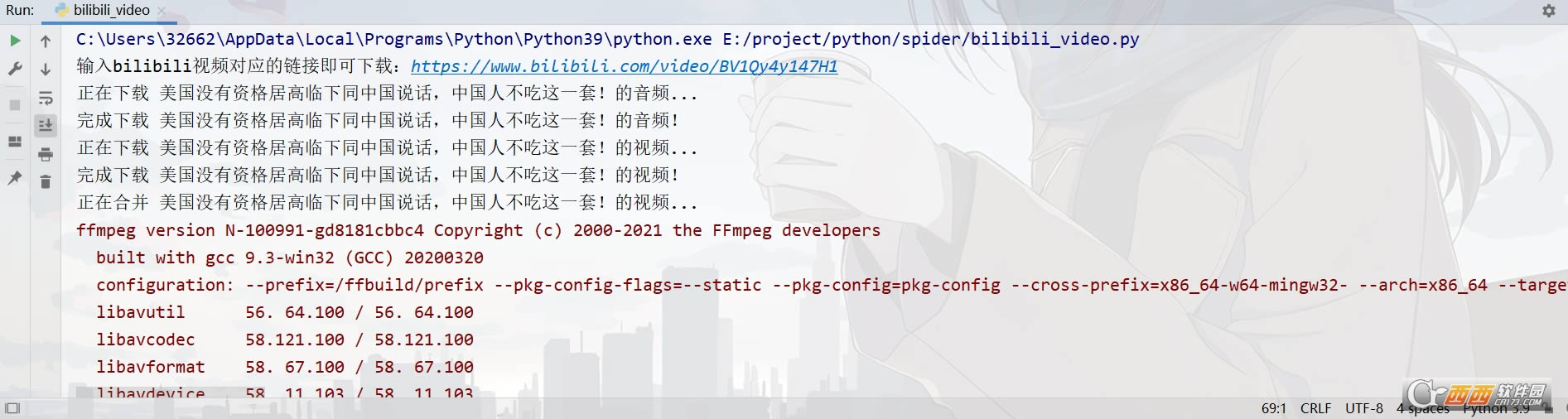
�������exeӦ�ó���������ƵURL�������ء�
������ϣ�
……
��������������� >>���ظ�������
��������������� >>���ظ�������